Building SQL Server Indexes in Ascending vs Descending Order
Written By: Edgewood Solutions Engineers -- 9/25/2007Problem
When building indexes often the default options are used to create an index which creates the index in ascending order. This is usually the most logical way of creating an index, so the newest data or smallest value is at the top and the oldest or biggest value is at the end. Although searching an index works great by creating an index this way, but have you ever thought about the need to always return the most recent data first and ways you can create an index in descending order so the most recent data is always at the top of the index? Let's take a look at how this works and the advantages of creating an index in descending vs ascending order.
Solution
When creating an index you have the option to specify whether the index is created in ascending or descending order. This can be done simply by using the key word ASC or DESC when creating the index as follows. The following examples all use the AdventureWorks sample database.
Create index in descending order:
| CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate] ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] DESC ) |
Create index in ascending order:
| CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate] ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] ASC ) |
Let's take a look at a couple of queries and query plans to see how this differs and if there is any advantage.
Example 1
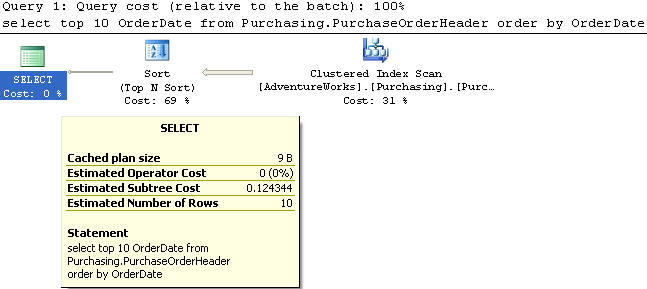
In this example we are using the PurchaseOrderHeader table to select the top 10 records and just the OrderDate column from the table sorted by OrderDate in ascending order. There is no index on the OrderDate column.
This query does a Clustered Index Scan and has a cost of 0.124344.
Example 2
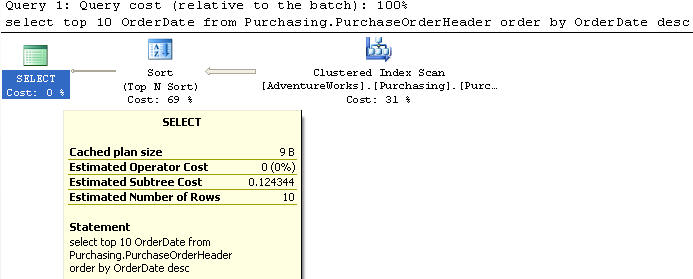
In this example we are using the PurchaseOrderHeader table to select the top 10 records and just the OrderDate column from the table sorted by OrderDate in descending order. There is no index on the OrderDate column.
This query does a Clustered Index Scan and has a cost of 0.124344 which is the same as above.
Example 3
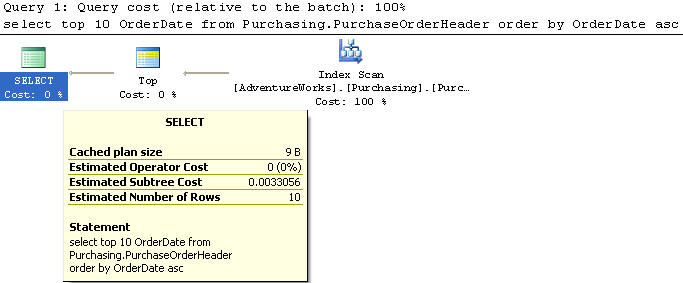
In this example we create an index on the OrderDate in ascending order.
We are using the PurchaseOrderHeader table to select the top 10 records and just the OrderDate column from the table sorted by OrderDate in ascending order.
This query does an Index Scan on the new index and has a cost of 0.0033056 which is much better than our previous value of 0.124344.
So from this we can see that adding the index does make this query much faster.
Example 4
In this example we created an index on the OrderDate in ascending order.
We are using the PurchaseOrderHeader table to select the top 10 records and just the OrderDate column from the table sorted by OrderDate in descending order.
This query does an Index Scan on the new index and has a cost of 0.0033056 which is the same as Example 3.
Take note that though the index was created in ascending order, getting the data in descending order is just as fast as getting the data in ascending order.
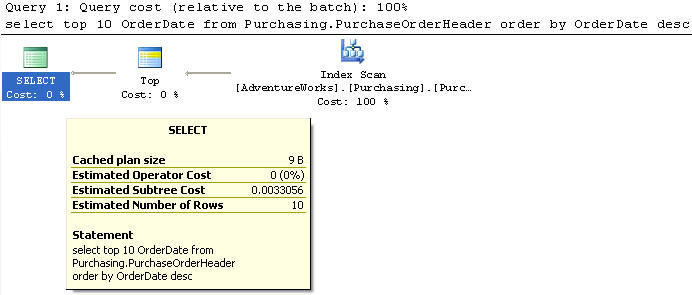
Example 5
Even though we already showed that selecting the data in descending order against an ascending index does not make a difference, let's just do a check to make sure.
In this example we created an index on the OrderDate in descending order.
We are using the PurchaseOrderHeader table to select the top 10 records and just the OrderDate column from the table sorted by OrderDate in ascending order.
This query does an Index Scan on the new index and has a cost of 0.0033056 which is the same as above, so there is no difference at all.
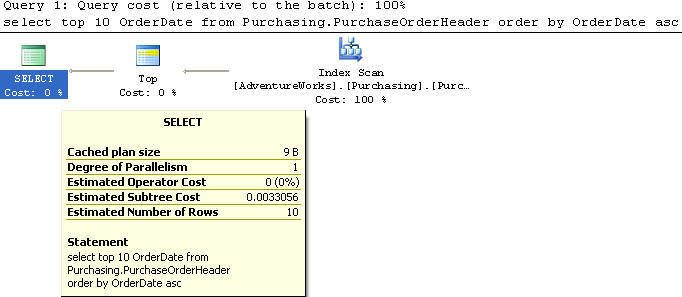
Another thing to look at is having the need to sort some of the columns in ascending order and other columns in descending order.
Example 6
In this example we created an index on the OrderDate in ascending order and SubTotal in ascending order.
| CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate] ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] ASC, [SubTotal] ASC ) |
We are using the PurchaseOrderHeader table to select the top 10 records and the OrderDate and SubTotal column from the table sorted by OrderDate in ascending order and the SubTotal in ascending order.
This query does an Index Scan and has a cost of 0.0033123.
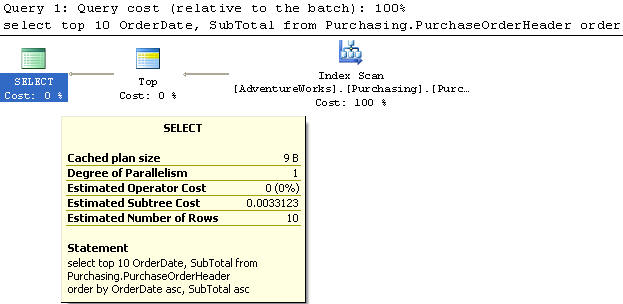
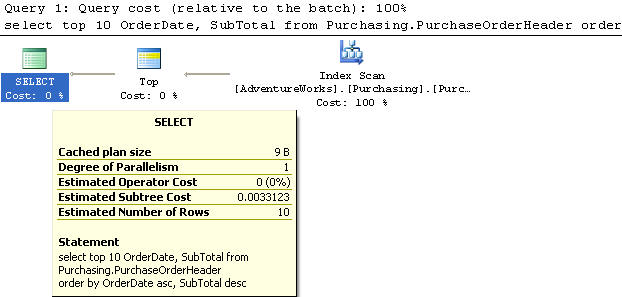
Example 7
In this example we created an index on the OrderDate in ascending order and SubTotal in ascending order..
We are using the PurchaseOrderHeader table to select the top 10 records and the OrderDate and SubTotal column from the table sorted by OrderDate in ascending order and the SubTotal in descending order.
This query does an Index Scan and has a cost of 0.102122. Having this index this way does not help much, since 84% of the work is done in the Sort operation.
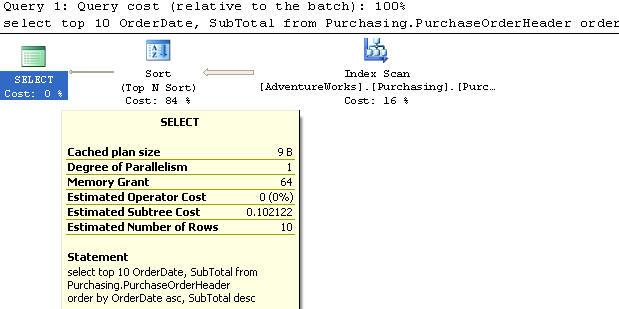
Example 8
In this example we created an index on the OrderDate in ascending order and SubTotal in descending order.
| CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate] ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] ASC, [SubTotal] DESC ) |
We are using the PurchaseOrderHeader table to select the top 10 records and the OrderDate and SubTotal column from the table sorted by OrderDate in ascending order and the SubTotal in descending order.
This query does an Index Scan and has a cost of 0.0033123. Having this index created this way helps out in a a big way. The Sort operation has now disappeared.
Summary
As we have shown creating an index in ascending or descending order does not make a big difference when there is only one column, but when there is a need to sort data in two different directions one column in ascending order and the other column in descending order the way the index is created does make a big difference.
Next Steps
- Next time you create indexes keep the above in mind. Don't worry so much about creating your single column index in either ascending or descending order
- If you have the need to create a multi-column index keep in mind the improvements that can be made if you create the index based on the way the data is accessed.