
Problem
Sometimes there is a need to process files in a folder, but first you need to determine which files need to be processed compared to older files that have already been processed. There are several ways that this can be done, but in this tip I show you a way this can be done using SQL Server and XML.
To further illustrate the issue I have set this up into three folders:
Source - files to be processed
Destination - files that have been processed
NewFiles - holding folder for new files to be processed after they have been compared
Elaborating the problem in depth, let’s say I have three text files (or any type of file) in the Source folder and the Destination folder contains two files. The problem is to identify differences between the files in the Source and Destination folders and copy all the modified or new files from the Source Folder to the folder NewFiles.
Shown below are the set of files with their modified date in the Source folder:
Shown below are the set of files with their modified date in Destination folder:
Looking at the images above, it is clear that Source Folder contains one extra file ‘text3’ and one modified file ‘text2’.
I want to compare the files in these two folders and copy the modified file (text2) and the new file (text3) into folder NewFiles.
SolutionMy first task was to get all the files from the specified folder. This can be achieved via the ‘DIR’ command of DOS. DOS commands can be executed in SQL Server through xp_cmdshell system stored procedure, but it needs to be configured first.
The below code creates a new stored procedure called "MakeXML" which will create a XML document of all of the files in a folder. The code does a few things which you can either turn on or off as desired.
It first drops stored procedure MakeXML so it can create a new sp with this name
It enables xp_cmshell so we can shell out to DOS to get the folder listing
It does a DIR command against the specified folder with the /O-D parameter to order the list by modified date
It then inserts the data into a temporary table
Deletes any rows from this table that are not files that we want to compare
Parses the modified date
Parses the filename
Then it creates this data as a temporary XML object
IF OBJECT_ID (N'MakeXML') IS NOT NULL DROP PROCEDURE MakeXML GO -------INPUT THE FILEPATH FOLDER AND IT WILL RETURN AN XML CREATE PROCEDURE MakeXML @FilePath VARCHAR(2000), @xmlFile XML OUTPUT AS DECLARE @myfiles TABLE (MyID INT IDENTITY(1,1) PRIMARY KEY,FullPath VARCHAR(2000),ModifiedDate datetime, FileName VARCHAR(100)) DECLARE @CommandLine VARCHAR(4000) ----Configure xp_cmdshell in 2005 -- To allow advanced options to be changed. EXEC sp_configure 'show advanced options', 1 -- To update the currently configured value for advanced options. RECONFIGURE -- To enable the feature. EXEC sp_configure 'xp_cmdshell', 1 -- To update the currently configured value for this feature. RECONFIGURE ----- run dir command on the path specified by ordering on the date modified SELECT @CommandLine =LEFT('dir "' + @FilePath + '" /O-D',10000) ------use xp_cmdshell stored procedure to run dos commands INSERT INTO @MyFiles (FullPath) EXECUTE xp_cmdshell @CommandLine ------Delete all the files that are other than .txt or can specify the file type you want to compare on DELETE FROM @MyFiles WHERE fullpath IS NULL OR Fullpath NOT LIKE '%.txt%' ------Separate the modified date from the fullpath UPDATE @myfiles SET ModifiedDate=SUBSTRING(fullpath,1,PATINDEX('%[AP]M%',fullpath)+1) ------Separate out FileName from fullpath UPDATE @myfiles SET FileName=SUBSTRING(fullpath,40,LEN(fullpath)) -----Make an xml out of separated ModifiedDate,FileName columns and SET the OUTPUT parameter SELECT @xmlFile=(SELECT ModifiedDate,FileName FROM @MyFiles FOR XML PATH('FILE'), ROOT('ROOT') ) GO
For our example the stored procedure would return XML for the Source folder ordered on modified date as shown below.
For our example the stored procedure would return XML for the Destination folder ordered on modified date as shown below.
Now, the next task is to compare the two XML documents from Source and Destination, this is achieved by the following stored procedure.
It takes three input parameters
@Sourcepath which is ‘D:\Source’
@DestPath is ‘D:\Destination’ and
@NewFilesPath as ‘D:\NewFiles’
IF OBJECT_ID (N'CompareXML') IS NOT NULL DROP PROCEDURE CompareXML GO --------COMPARE XML CREATE PROCEDURE CompareXML @SourcePath VARCHAR(255), @DestPath VARCHAR(255), @NewFilesPath VARCHAR(255) AS DECLARE @SourceXML AS XML,@DestXML AS XML ---Call the MakeXML sp to return the XML for Source and Destination Folders EXECUTE MakeXML @SourcePath,@SourceXML OUTPUT EXECUTE MakeXML @DestPath,@DestXML OUTPUT DECLARE @CURSOR_File AS CURSOR ---------Join both the tables retrieved from xml on filename and get all the files having modifieddate mismatch ---------Fetch all the values into a cursor SET @CURSOR_File= CURSOR FOR SELECT A.FNAME FROM ( SELECT N.value('ModifiedDate[1]','varchar(100)') AS MDATE , N.value('FileName[1]','varchar(100)') AS FNAME FROM @SourceXML.nodes('ROOT/FILE') AS X(N) )A INNER JOIN ( SELECT N.value('ModifiedDate[1]','varchar(100)') AS MDATE , N.value('FileName[1]','varchar(100)') AS FNAME FROM @DestXML.nodes('ROOT/FILE') AS X(N) )B ON A.FNAME=B.FNAME AND A.MDATE<>B.MDATE UNION ----------Fetch all the extra files in the source folder SELECT A.FNAME FROM ( SELECT N.value('ModifiedDate[1]','varchar(100)') AS MDATE , N.value('FileName[1]','varchar(100)') AS FNAME FROM @SourceXML.nodes('ROOT/FILE') AS X(N) )A LEFT OUTER JOIN ( SELECT N.value('ModifiedDate[1]','varchar(100)') AS MDATE , N.value('FileName[1]','varchar(100)') AS FNAME FROM @DestXML.nodes('ROOT/FILE') AS X(N) )B ON A.FNAME=B.FNAME WHERE b.fname IS NULL DECLARE @file AS VARCHAR(255) DECLARE @Command AS VARCHAR(500) --------First copy all the files found mismatched on modified date into @NewFilesPath OPEN @CURSOR_File FETCH NEXT FROM @CURSOR_File INTO @file WHILE @@Fetch_Status=0 BEGIN SET @Command='xcopy "'+@SourcePath+'\'+ @file+ '" "' + @NewFilesPath + '"' EXEC xp_cmdshell @Command,no_output FETCH NEXT FROM @CURSOR_File INTO @file END CLOSE @CURSOR_File DEALLOCATE @CURSOR_File GO
The CompareXML stored procedure above will first call the ‘MakeXML’ sp and get the source and destination xml. It will fetch all the values from the nodes of both the XML documents and make two types of comparison on those.
First the comparison would be on the basis of filename having different modified date values.
The second comparison will fetch all the files from Source folder that do not exist in Destination folder.
The output of this is put into a Cursor so that such files are then copied to the ‘NewFiles’ folder one by one using the DOS xcopy command.
After the two stored procedures have been created the code is executed as follows:
EXECUTE CompareXML @SourcePath='D:\Source', @DestPath='D:\Destination', @NewFilesPath='D:\NewFiles'
Based on our example the "NewFiles" folder will now look like this.
The NewFiles folder has the same set of files which had a different modified date and the file which was extra in the Source folder. Now, just copy the files from this NewFiles folder to Destination folder.
The problem of comparing files based on modified date and filename has been drastically reduced compared to doing it manually.
Monday, May 11, 2009
Friday, May 8, 2009
How to Export data from SQL Server to Excel
Problem
Exporting data from SQL Server to Excel seems like a reasonably simple request. I just need to write out a few reports for users on a regular basis, nothing too fancy, the same basic report with a few different parameters. What native SQL Server options are available to do so? Do I need to learn another tool or can I use some T-SQL commands? Does SQL Server 2005 offer any new options to enhance this process?
Solution
Exporting data from SQL Server to Excel can be achieved in a variety of ways. Some of these options include Data Transformation Services (DTS), SQL Server Integration Services (SSIS) and Bulk Copy (BCP). Data Transformation Services (SQL Server 2000) and SQL Server Integration Services (SQL Server 2005) offers a GUI where widgets can be dragged and dropped Each option has advantages and disadvantages, but all can do the job. It is just a matter of your comfort level with the tools and the best solution to meet the need.
Another option that is available directly via the T-SQL language is the OPENROWSET command (SQL Server 2000 and SQL Server 2005). This command can be called directly in any stored procedure, script or SQL Server Job from T-SQL. Below outlines the full syntax available:
Source - SQL Server 2005 Books Online
Below is a simple example of writing out the Job name and date to Sheet1 of an Excel spreadsheet in either SQL Server 2005 or 2000:
| INSERT INTO OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'Excel 8.0;Database=C:\testing.xls;', 'SELECT Name, Date FROM [Sheet1$]') SELECT [Name], GETDATE() FROM msdb.dbo.sysjobs GO |
Using the OPENROWSET command creates two caveats. The first caveat is the need to have an Excel spreadsheet serve as a template in the needed directory with the correct worksheets and columns. Without this the you would receive an error message. The second caveat is that it is necessary to enable the OPENROWSET command with the SQL Server 2005 Surface Area Configuration utility. Note - This step is not needed for SQL Server 2000. With the loop example you could copy and paste the Excel spreadsheet and load the data as needed.
Although the example above is very simple, you could integrate this simple example into your code. For example, if you had the need to write out a number of reports in the same format, you could loop (WHILE loop or Cursor) over the records and write them out to different Excel spreadsheets based on the name or report type. In addition, you could integrate this code with either SQL Server 2000 mail or Database mail (SQL Server 2005) and mail the results to the users with very little effort and build the process entirely with T-SQL.
Saturday, April 18, 2009
SQL Server UDF to pad a string
Problem
Unlike other relational database management systems that shall remain nameless, SQL Server's underlying coding language, T/SQL, does not have a built-in function for padding string values. I recently took it upon myself to create my own and as you'll see I got a little carried away.
Solution
The task seems simple enough: create a user-defined function that will allow padding of a string value with a finite count of a desired character. What ended up as an experiment out of necessity became a slightly more-involved function once I decided that padding position should be customizable to meet the end user's needs.
While Transact-SQL (T/SQL) does not offer a comparable function similar to LPAD or RPAD available in other RDBMSs, the SQL Server Professional does have the REPLICATE() function that can be used to build a simple user-defined function that can be used to pad a string. Let's take a look at the REPLICATE() function and what it offers before moving on to the code for the custom padding function.
REPLICATE (string_expression ,integer_expression) will allow you to replicate a character string (the string_expression parameter the number of times consecutively per the integer_expression parameter).
A simple example of this function is presented below:
SELECT REPLICATE('ABCDE|', 3)
|
Whereas the REPLICATE() function will allow you to return a string to a maximum size of 8000 bytes, the function I'll be creating will be based upon an output value of varchar(100). You will be able to modify this value to fit your needs, however I very rarely have a need to pad a string value greater than even 20 characters. I thought it worthwhile to create a single function for padding either to the left or right of the unpadded string. Then it became interesting, what if for some reason you wished to pad the center of the string? What about padding both the left and right sides of the string evenly? Whether you use those options or not, the functionality is there. The code below represents the function I've created.
CREATE FUNCTION [dbo].[usp_pad_string] |
The function expects four parameters:
- @string_unpadded - the raw string value you wish to pad.
- @pad_char - the single character to pad the raw string.
- @pad_count - the amount of times to repeat the padding character
- @pad_pattern - an integer value that determines where to insert the pad character
- 0 - all pad characters placed left of the raw string value (pad left)
- 1 - all pad characters placed right of the raw string value (pad right)
- 2 - all pad characters placed at the midpoint of the raw string value (pad center)
- 3 - the raw string value will be centered between the pad characters (pad ends)
Notes
- If either of the length of the supplied @pad_count or @string_unpadded values are odd, centering will be affected. We will show that behavior in the samples presented below.
- Since the return value of the function is limited to 100 characters, the length of parameter corresponding to the unpadded string must be sized according to allow for padding. The length of the return value and this parameter are completely customizable to fit your needs.
- While the
REPLICATE()function allows you to pad more than a single character, this function expects you'll only pad a single character.
Example 1 Evenly-Distributable Padding
--Even distribution possible |
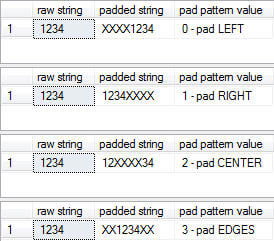
The previous set of examples shows what results to expect when the parameters are evenly distributed. What happens though when this is not possible? This occurs under two situations: you are attempting to center-pad a raw string that has an odd number of characters or you're trying to pad an odd number of characters using the pad edges option (@pad_pattern = 3). I am not going to show you some method for splitting an odd string at a quantum level. Sorry, I am not all that brilliant as it is. Therefore I had to make a judgment call on how the behavior is going to occur using the structure of the three dimensions we have to work with here currently. The following examples will present how this function will behave.
Example 2 - Center-Pad an Odd-Length Raw String
--Pad Center |
![]()
Example 3 - Center-Edges an Odd Number of Times
--Pad Edges |
![]()
As you can see, the padding will be right-heavy in both cases. Though I doubt you'll have much use for center or edge-padding strings in Transact-SQL, you never really know.
Padding is a frequent need in returning string results to the end user of a RDBMS. This function allows you to do so as if the functionality existed inherently in T-SQL.
Tuesday, April 7, 2009
SQL Server Cursor Examples
Here's some Examples on SQL Server Cursor
Problem
In my T-SQL code I always use set based operations. I have been told these types of operations are what SQL Server is designed to process and it should be quicker than serial processing. I know cursors exist but I am not sure how to use them. Can you provide some cursor examples? Can you give any guidance on when to use cursors? I assume Microsoft created them for a reason so they must have a place where they can be used in an efficient manner.
Solution
In some circles cursors are never used, in others they are a last resort and in other groups they are used regularly. In each of these camps they have different reasons for their stand on cursor usage. Regardless of your stand on cursors they probably have a place in particular circumstances and not in others. So it boils down to your understanding of the coding technique then your understanding of the problem at hand to make a decision on whether or not cursor based processing is appropriate or not. To get started let's do the following:
- Look at an example cursor
- Break down the components of the cursor
- Provide additional cursor examples
- Analyze the pros and cons of cursor usage
Example Cursor
Here is an example cursor from tip Simple script to backup all SQL Server databases where backups are issued in a serial manner:
DECLARE @name VARCHAR(50) -- database name |
Cursor Components
Based on the example above, cursors include these components:
- DECLARE statements - Declare variables used in the code block
- SET\SELECT statements - Initialize the variables to a specific value
- DECLARE CURSOR statement - Populate the cursor with values that will be evaluated
- NOTE - There are an equal number of variables in the DECLARE
CURSOR FOR statement as there are in the SELECT statement. This could be 1 or many variables and associated columns.
- NOTE - There are an equal number of variables in the DECLARE
- OPEN statement - Open the cursor to begin data processing
- FETCH NEXT statements - Assign the specific values from the cursor to the variables
- NOTE - This logic is used for the initial population before the WHILE statement and then again during each loop in the process as a portion of the WHILE statement
- WHILE statement - Condition to begin and continue data processing
- BEGIN...END statement - Start and end of the code block
- NOTE - Based on the data processing multiple BEGIN...END statements can be used
- Data processing - In this example, this logic is to backup a database to a specific path and file name, but this could be just about any DML or administrative logic
- CLOSE statement - Releases the current data and associated locks, but permits the cursor to be re-opened
- DEALLOCATE statement - Destroys the cursor
Additional Cursor Examples
In the example above backups are issued via a cursor, check out these other tips that leverage cursor based logic:
- Managing SQL Server Database Fragmentation
- SQL Server script to rebuild all indexes for all tables and all databases
- SQL Server Index Analysis Script for All Indexes on All Tables
- Standardize your SQL Server data with this text lookup and replace function
- Automating Transaction Log Backups for All SQL Server Databases
- Searching and finding a string value in all columns in a SQL Server table
- Scripting SQL Server Database Objects Using DMO (Distributed Management Objects)
- Script to create commands to disable, enable, drop and recreate Foreign Key constraints in SQL Server
- Capacity Planning for SQL Server 2000 Database Storage
- Automate Restoration of Log Shipping Databases for Failover in SQL Server 2000
- Determining space used for each table in a SQL Server database
- Auditing Windows Groups from SQL Server
- SQL Server Find and Replace Values in All Tables and All Text Columns
- Easing the SQL Server Database Capacity Planning Burden
- Index Metadata and Statistics Update Date for SQL Server
Cursor Analysis
The analysis below is intended to serve as insight into various scenarios where cursor based logic may or may not be beneficial:
- Online Transaction Processing (OLTP) - In most OLTP environments, SET based logic makes the most sense for short transactions. Our team has run into a third party application that uses cursors for all of its processing, which has caused issues, but this has been a rare occurrence. Typically, SET based logic is more than feasible and cursors are rarely needed.
- Reporting - Based on the design of the reports and the underlying design, cursors are typically not needed. However, our team has run into reporting requirements where referential integrity does not exist on the underlying database and it is necessary to use a cursor to correctly calculate the reporting values. We have had the same experience when needing to aggregate data for downstream processes, a cursor based approach was quick to develop and performed in an acceptable manner to meet the need.
- Serialized processing - If you have a need to complete a process in serialized manner, cursors are a viable option.
- Administrative tasks - Many administrative tasks need to be executed in a serial manner, which fits nicely into cursor based logic, but other system based objects exist to fulfill the need. In some of those circumstances, cursors are used to complete the process.
- Large data sets - With large data sets you could run into any one or more of the following:
- Cursor based logic may not scale to meet the processing needs.
- With large set based operations on servers with a minimal amount of memory, the data may be paged or monopolize the SQL Server which is time consuming can cause contention and memory issues. As such, a cursor based approach may meet the need.
- Some tools inherently cache the data to a file under the covers, so processing the data in memory may or may not actually be the case.
- If the data can be processed in a staging SQL Server database the impacts to the production environment are only when the final data is processed. All of the resources on the staging server can be used for the ETL processes then the final data can be imported.
- SSIS supports batching sets of data which may resolve the overall need to break-up a large data set into more manageable sizes and perform better than a row by row approach with a cursor.
- Depending on how the cursor or SSIS logic is coded, it may be possible to restart at the point of failure based on a checkpoint or marking each row with the cursor. However, with a set based approach that may not be the case until an entire set of data is completed. As such, troubleshooting the row with the problem may be more difficult.
Cursor Alternatives
Below outlines alternatives to cursor based logic which could meet the same needs:
- Set based logic
- SQL Server Integration Services (SSIS) or Data Transformation Services (SSIS)
- WHILE loop
- COALSCE
- sp_MSforeachdb
- sp_MSforeachtable
- Here is a tip with example code - http://www.mssqltips.com/tip.asp?tip=1274
- CASE expression
- Repeat a batch with the GO command
Saturday, March 7, 2009
SQL Server user defined function to convert MSDB integer value to time value
Problem
In a recent tip I outlined a process for converting a date, stored as an integer into a datetime data type. Date and time information for run history of SQL Server Agent jobs is stored within the msdb..sysjobshistory table as an integer data type, not as a datetime as one would expect. Most likely for at least two reasons:
- This structure is a legacy implementation from the earliest days of SQL Server
- The values are stored in separate run_date and run_time columns and until SQL Server 2008 there was not a time data type per se
As promised, this tip picks up where we left off. On converting the integer-typed run_time into a format that is more user friendly for presentation purposes.
We will still be using the same metadata repository for the SQL Server instances I administer. From the previous tip, you may remember that one of the metrics I track is based upon Job History success and failure. This information comes directly from the msdb..sysjobhistory table that resides upon each SQL Server instance.
Solution
Let's take a look again at a simple query against the msdb..sysjobshistory and msdb..sysjobs tables that hold the data we're interested in:
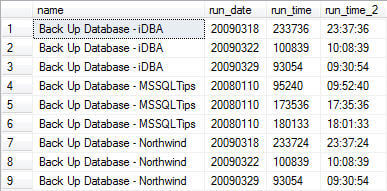
| sysJobHistory and sysJobs Data |
| SELECT SJ.name, SJH.run_date, SJH.run_time FROM msdb.dbo.sysjobhistory SJH INNER JOIN msdb.dbo.sysjobs SJ ON SJH.job_id = SJ.job_id WHERE SJH.step_id = 0 ORDER BY SJ.name GO |
|
|
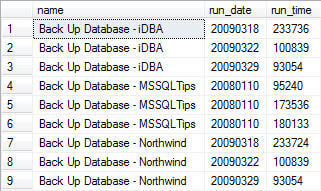
We have already covered how to convert run_date (as integer) to a datetime data type that can then be used in date calculations such as DATEADD(), DATEDIFF(), DATENAME() or DATEPART(). The purpose of this tip is to convert the run_time value (stored as an integer data type) into a format that is more presentable for end users. This can be accomplished in two manners, both outlined below. The later is a standalone user-defined function (UDF) the second takes into consideration an additional UDF outlined recently in a tip on padding string values. Reliance on this second UDF reduces the amount of code necessary. I'll be presenting the actual query execution plan for a simple query using each process so you can determine which option is the best for your environment.
As a point of reference, the msdb..sysjobhistory.run_time values are stored as an integer, in the pattern of hhmmss. Unfortunately for us, since this is an integer value, single digit values do not include a preceding zero (9:00 am for example is stored as 900, midnight as simply 0).
Option One - Standalone UDF
Let's take a look at our first option to address this problem which is a standalone UDF.
| Option One: The Standalone UDF |
| CREATE FUNCTION dbo.udf_convert_int_time_1 (@time_in INT) RETURNS VARCHAR(8) AS BEGIN DECLARE @time_out VARCHAR(8) SELECT @time_out = CASE LEN(@time_in) WHEN 6 THEN LEFT(CAST(@time_in AS VARCHAR(6)),2) + ':' + SUBSTRING(CAST(@time_in AS VARCHAR(6)), 3,2) + ':' + RIGHT(CAST(@time_in AS VARCHAR(6)), 2) WHEN 5 THEN '0' + LEFT(CAST(@time_in AS VARCHAR(6)),1) + ':' + SUBSTRING(CAST(@time_in AS VARCHAR(6)), 2,2) + ':' + RIGHT(CAST(@time_in AS VARCHAR(6)), 2) WHEN 4 THEN '00' + ':' + LEFT(CAST(@time_in AS VARCHAR(6)),2) + ':' + RIGHT(CAST(@time_in AS VARCHAR(6)), 2) ELSE '00:00:00' --midnight END --AS converted_time RETURN @time_out END GO |
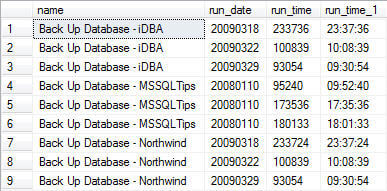
The function accepts a single parameter, the integer data type time value passed to it. Depending on the length of the parameter, the output value is formatted accordingly and the result is returned. Revising the first query in this tip to include the results of this UDF applied to each record is presented below along with it's associated output and actual execution plan.
| Sample Execution |
SELECT SJ.[name], SJH.[run_date], SJH.[run_time], |
|
|
|
|
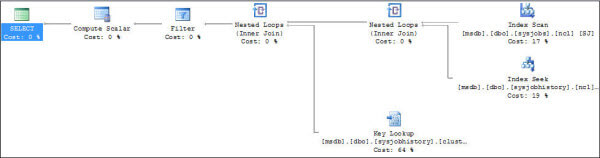
Option Two: Reliance on Padding of Input Variable
Recently, I published a tip on MSSQLTips.com on padding string values in Microsoft SQL Server. We will be using the UDF presented in that tip to simplify the code presented above. Afterwards we'll see what possible effect that has on performance by comparing the actual execution plan against the execution plan for the first iteration of the UDF shown above.
| Option Two: Reliance on Padding of Input Variable |
| CREATE FUNCTION dbo.udf_convert_int_time_1 (@time_in INT) RETURNS VARCHAR(8) AS BEGIN DECLARE @time_out VARCHAR(8) SELECT @time_out = CASE LEN(@time_in) WHEN 6 THEN LEFT(CAST(@time_in AS VARCHAR(6)),2) + ':' + SUBSTRING(CAST(@time_in AS VARCHAR(6)), 3,2) + ':' + RIGHT(CAST(@time_in AS VARCHAR(6)), 2) WHEN 5 THEN '0' + LEFT(CAST(@time_in AS VARCHAR(6)),1) + ':' + SUBSTRING(CAST(@time_in AS VARCHAR(6)), 2,2) + ':' + RIGHT(CAST(@time_in AS VARCHAR(6)), 2) WHEN 4 THEN '00' + ':' + LEFT(CAST(@time_in AS VARCHAR(6)),2) + ':' + RIGHT(CAST(@time_in AS VARCHAR(6)), 2) ELSE '00:00:00' --midnight END --AS converted_time RETURN @time_out END GO |
By utilizing the usp_pad_string() function we can eliminate the CASE code structure from the dbo.udf_convert_int_time_2 UDF. The padding function expects four parameters: the string value to pad, the padding character, the number of instances to apply the pad, and the padding placement. Please review the full structure of the usp_pad_string UDF in the original article. It will pad the integer value so that further processing can be consistently applied without concern for length. Running a comparable query to the one previously presented returns the following results and execution plan.
| Sample Execution |
SELECT SJ.[name], SJH.[run_date], SJH.[run_time], |
|
|
|
|
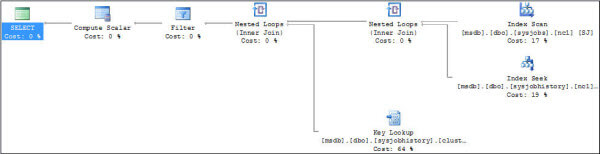
The additional function call to the padding UDF has no apparent additional overhead on the execution of the query. Which option you choose would be up to you, dependent upon your preference for UDF reliance and embedding of UDFs. Ultimately this process is based upon conversion of time-of-day data into a presentable format. While the CONVERT() function is capable of converting string values to presentable formats when passed datetime values, there is no functionality for time-only values.
Subscribe to:
Comments (Atom)
